Introducing ChatQA-1.5: Surpassing GPT-4 on Conversational QA and RAG
Model Weights🤗 Evaluation Data🤗 Training Data🤗 Retriever🤗 Paper
Today (May 3rd, 2024), we release ChatQA-1.5, which excels at conversational question answering (QA) and retrieval-augmented generation (RAG). ChatQA-1.5 is developed using an improved training recipe from ChatQA paper, and it is built on the top of the Llama-3 base model. Specifically, we incorporate more conversational QA data to enhance its tabular and arithmetic calculation capability. ChatQA-1.5 has two variants: Llama3-ChatQA-1.5-8B and Llama3-ChatQA-1.5-70B. We share the model weights, evaluation data, training data, and SFT recipe for future study.
ChatRAG Bench
We release ChatRAG Bench: a benchmark for evaluating a model's conversational QA capability over documents or retrieved context. ChatRAG Bench consisting of 10 datasets: Doc2Dial, QuAC, QReCC, TopioCQA, INSCIT, CoQA, HybriDialogue, DoQA, SQA, ConvFinQA. ChatRAG Bench covers a wide range of documents and question types, which require models to generate responses from long context, comprehend and reason over tables, conduct arithmetic calculations, and indicate when questions cannot be found within the context.Superior Accuracy on RAG and Conversational QA
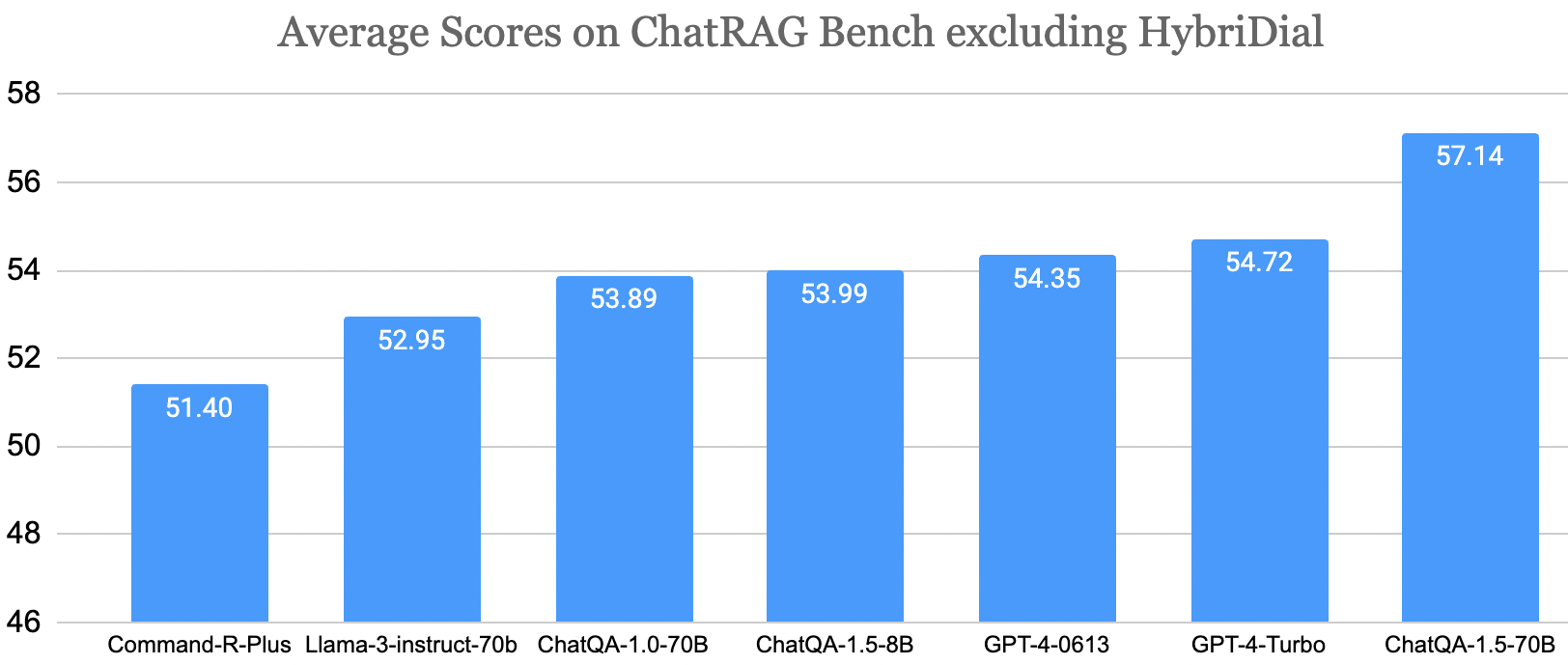
Evaluation of Unanswerable Scenario
ChatRAG Bench also includes evaluations for the unanswerable scenario, where we evaluate models' capability to determine whether the answer to the question can be found within the given context. Equipping models with such capability can substantially decrease the likelihood of hallucination.| Command-R-Plus | Llama-3-instruct-70b | GPT-4-0613 | GPT-4-Turbo | ChatQA-1.0-70B | ChatQA-1.5-8B | ChatQA-1.5-70B | |
|---|---|---|---|---|---|---|---|
| Average | 68.11 | 76.42 | 80.73 | 80.47 | 77.25 | 75.57 | 71.86 |
We use QuAC and DoQA datasets which have such unanswerable cases to evaluate such capability. We use both answerable and unanswerable samples for this evaluation. Specifically, for unanswerable case, we consider the model indicating that the question cannot be answered as correct, and as for answerable cases, we consider the model not indicating the question is unanswerable as correct (i.e., the model giving an answer). In the end, we calculate the average accuracy score of unanswerable and answerable cases as the final metric.
Other Evaluations
Evaluation on Single-Turn QA and RAG Benchmark
| Models | Average | NQ | TriviaQA | HotpotQA |
|---|---|---|---|---|
| Atlas (11B) (Izacard et al., 2023) | 39.4 | 26.7 | 56.9 | 34.7 |
| Raven (11B) (Huang et al., 2023) | - | 29.6 | 65.7 | - |
| RECOMP (20B) (Xu et al., 2024) | 42.1 | 37.0 | 59.0 | 30.4 |
| InstructRetro (43B) (Wang et al., 2024) | - | 38.9 | 65.6 | - |
| RePlug (65B) (Shi et al., 2023) | 44.5 | 28.8 | 72.6 | 32.0 |
| RA-DIT (65B) (Lin et al., 2024) | 50.1 | 35.2 | 75.4 | 39.7 |
| Llama3-instruct-8B (Meta, 2024) | 42.5 | 30.9 | 70.7 | 26.0 |
| Llama3-instruct-70B (Meta, 2024) | 53.6 | 42.7 | 82.4 | 35.6 |
| Llama3-ChatQA-1.5-8B | 52.3 | 42.4 | 81.0 | 33.5 |
| Llama3-ChatQA-1.5-70B | 58.7 | 47.0 | 85.6 | 42.2 |
We further evaluate Llama3-ChatQA-1.5 models on knowledge-intensive single-turn QA datasets: Natural Questions (NQ), TriviaQA, and HotpotQA from the KILT Benchmark, and compare them against frontier RAG models. We use the Dragon retriever to obtain the most relevant contexts and perform a one-time retrieval for all datasets. We find that, despite its significantly smaller model size, Llama3-ChatQA-1.5-8B performs better than RA-DIT (65B). Llama3-ChatQA-1.5-70B remarkably outperforms existing frontier RAG models.
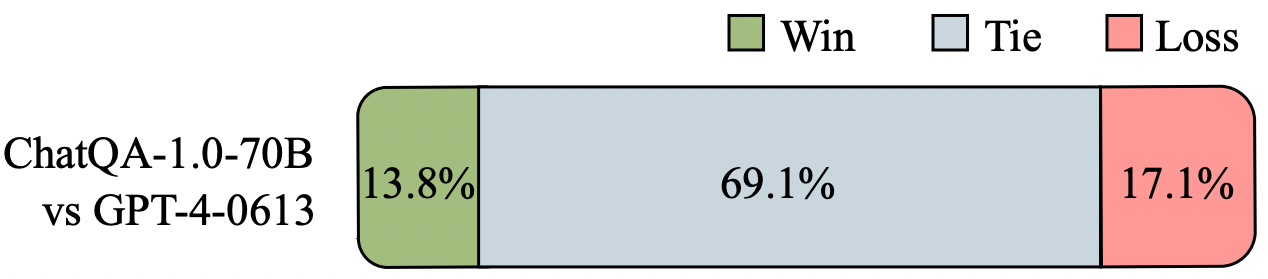
Human Evaluations
Training Datasets
We release the training datasets described in ChatQA paper.Conversational QA Retriever
We release the dragon multi-turn query retriever for the conversational QA task. The details of this retriever are described in ChatQA paper.Citation
@article{liu2024chatqa,
title={ChatQA: Surpassing GPT-4 on Conversational QA and RAG},
author={Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2401.10225},
year={2024}}